|
After spending some time thinking on how to use Myo for text input and experimenting a little bit we think we can share some of our findings. Strengths: Myo does have some strengths when compared to other input devices. 1- It is minimally intrusive and can be used for mobile interaction. 2- It can sense hand poses. 3- It has IMU with accelerometers and gyros to detect arm movement. Limitations: Some of them are due to myo's specific sensing technology 1- There are only a few hand poses that the MYO can recognize 2- It seems to be sensitive to the initial calibration. 3- Hand poses can be stressful and difficult to change between them (this is required for proper detection). 4- Many false negatives (generally for the less stressful poses). Some are shared with other 3D interface devices: 1-Live mic problem - hand poses can be activated by accident, though rarely. 2-Lack of spatial frame of reference. Ideas: To overcome the limitations we tried several things in our design: 1-Restrict the set of hand poses used frequently to the ones that offer less false negatives (wave-in and wave-out). 2-Use the initial set of recognized hand poses as primitives to obtain a larger set ( add gesture and gyroscope data). 3-Allow for continuation of gestures. Since most gestures are stressful, allow to user to specify parameters by continuing the motion. 4-Try to use relative hand positions instead of using absolute space positions. 5-Try to transition between gestures that are easy to perform (some gestures are hard to transition e.g. between fist an open hand). We hope that these ideas are useful to others designing interaction techniques using Myo.
1 Comment
On a previous blog entry I mentioned that Myo could be an interesting device for bare hand text input. After being able to play with it for a while I can offer my first impressions. The armband seems pretty well designed. It has no hard edges and the material feels good to touch. It is somewhat bulky and even though it is not heavy on the arm, the aesthetics might be more appealing to men. It also comes with small clips that you can use to tighten the band if you have thin arms. There are no buttons, just a USB connector for charging and a glowing logo in one of the pods.
The SDK recognizes five different hand poses: palm pointing left, right, spread fingers, fist and thumb to pinky. These poses can be combined with data from the IMU to create more complex patterns and detect movement. The API gives access to the pose detected, orientation data and the vibration motor. As we inferred the poses are fairly independent from the arm orientation, which allows more flexibility for design. The quality of the built in classifier is also good for a first version. We noticed some false negatives and false positives with the former being more common. Sometimes you need to repeat the same gesture several times before it gets acknowledged. In our limited experience the pinky to thumb seems the most difficult to recognize, which also correlates with the fact of it is the less stressful pose. Left and right hand poses are the most reliable, they are almost flawless. People seems to hold different opinions regarding which pose is the most tiresome, but in general all of them seems less fatiguing than we initially thought. In retrospect the engineers at Thalmic made a good choice in selecting the poses and the decision of shipping with only five of them was also wise. However, as a researcher I wish I could have access to more data. This would allow me to play with new algorithms or just select poses that make more sense for my particular task. I hope they change it on the future like Leap Motion did. It does not need to provide all EMG data, just the "tension" values for each group of muscles would suffice: palm, thumb, fingers. I do not believe they have constructed their classifier in this way but I think it can be done. This seems a good tradeoff between flexibility, simplicity and battery life.
As we spend more time with the armband we might need to adapt our original ideas for text input. If the gesture pinky-to-thumb end up being unreliable we might be tempted to remove it altogether from our design. The information from the IMU, on the other hand, may open more interesting directions for our work. We experimented with the rotation of the arm (roll), for example, and it seems pretty stable. Summing up, even with the current limitations Myo it is a very interesting device. It is ready for some new cool interaction propositions. Anyone ? Swype is a commercial text input system developed originaly by Swype Inc. an latter acquired by Nuance Communications. It was first presented at the TechCrunch50 in 2008. After that several similar keyboards appeared for smartphones.
In SHARK each word is also defined by a pattern drawn over a keyboard layout. In this work, however, the authors used the ATOMIK keyboard instead of a QWERTY. The ATOMIK was designed to minimized the gesture time between keys that are more frequently used. The authors argue that gesture input for words can be better than tapping letters if you are able design them in a way that require less visual precision. This explains why even though you require more travel time, it is still fast to input text with this technique. The authors, however, were targeting the use of the gestures as a shortcut for most used words. The ideia is that after training a user would be able to input words without using the keyboard as a guide. They created an alphabet for the most frequent 100 words. Words that were not on this group used normal tapping input. 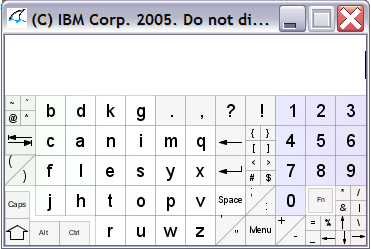 ATOMIK keyboard layout. In SHARK words are recognized using dynamic programming to compare the distance between the gesture and a template. The most similar word is returned. If only the direction and shape of the gestures are considered then some ambiguity still remain. The authors proposed that the initial or center position of the gesture could be used to solve this problem. In SHARK2 they improve upon the previous system by adding visual trace to the gestures (similar to what Swype does) and by assuring that every word could by entered by the same method. This more advanced system combined information from shape and location classifiers as well as a language model to increase the discrimination power. The inclusion of visual guided input works very well as an scaffolding technique. Even after using Swype for while, I don't think I was ever able to draw a word from memory alone.
Wearable devices will change the way we use and experience technology. Many challenges still need to be solved such as better integration with clothing, better battery lifetime and many questions regarding interaction. These devices can have very small displays or even no display at all. When this happens, common techniques such as keyboards and touch screens are not so useful anymore.  Google glass in a prescription frame. 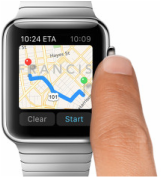 Apple Watch. Apple Watch. Today many wearables rely on a smartphone companion for internet connection and some advanced tasks, however many understand that decoupling from mobile devices is a necessary step to achieve the vision of a truly omnipresent and invisible technology. Connectivity is already on the way in devices like the Samsung S, which uses a mini-sim for direct 3G access. A good interaction technique would impact a lot the use of these devices. Apple has recognized that we need to come up with different ideas so it recently proposed using the watch crown as an interaction device. The main problem is that we usually want to increase the expressiveness of input not to narrow it. For this reason along the years we have supplemented keyboards with mouses, tablets and touch screens. By making smaller devices we inadvertently tend to scale down the interaction possibilities too. Two exceptions to this are voice and gestural input: since they are not physically attached to the input target they can maintain their power regardless of the device size. Voice recognition, unfortunately, has some obvious disadvantages if you are in a noise environment or don't want to bother nearby fellows. Together with Ayshwarya, I have been studying the possibility of developing a gesture-based text input technique as part of our work for a Natural User Interface class at Virginia Tech. We decided to go along a selection technique for letters instead of drawing/handwriting. We believe that selection has the potential of being much faster since you can create methods to choose a letter in constant time. In fact, with a few exceptions, most of the current input systems go in this way. Another trend is to use some kind of prediction or correction algorithm to minimize mistakes and effort during input. For selection, we noticed that three main actions are required: 1-Highlight a specific letter 2-Select the letter 3-Finish the word Touch based techniques implicitly highlight letters, since the user can tell from his hand position and tactile perception when no letter has been selected. Other input devices, however, may require an explicit designed disambiguation mechanism (such as a button) or use a technique that combines both highlighting and selection. Joysticks are a good example of the first group. They generally use a specific button to selected a highlighted item. On the other hand, Swype unifies the two actions: the drawing of the curve is used determine probable letters and then words. Another classic technique that combines highlighting and selection is the Dasher. In this technique the user continuously steer a cursor, which run over letters selecting them. Finally, the purpose of the last action is to enable the user to prematurely end the word input, based on suggestions from an autocomplete system. Regarding the input device, our first idea was to use Myo. This would theoretically allow users to input information using gestures and hand poses without the support of a desktop or computer, something more close to the wearable ideal.  Myo, from Thalmic Labs. Myo works by analyzing signals captured from your arms in a process called electromyography. The signals are processed by a classifier that can distinguish 5 different hand poses. The armband also contains an IMU (gyroscope, accelerometer and magnetometer) that can be used to track the relative position to the ground and the acceleration of the arm.
Next steps involve generating some options for input mapping and some way of evaluating them. Lets talk more about text input. What is common between the existing methods?
My first try culminated in the categorization of text input methods into four groups: 1-Physical keyboards 2-Drawing methods (grafitti, gesture for drawing) 3-Virtual keyboards (swype, virtual pointing) 4-Voice recognition This classification is far from being complete and definitive. Some techniques can combine more than one input method or can be considered borderline. For example, you can activate virtual keys by using gestures, your eye, touchscreens or hand poses. However this classification is enough to provide a start point for analysis. Keyboards are good for several reasons: you can use your 10 fingers, have a clear confirmation when the letter has been input and can use your muscle memory to type without looking at the keyboard. Drawing techniques such as Graffiti are good because they can leverage your knowledge of writing and the letter shapes to memorize a large number of commands easily. Virtual keyboards use the fact that they are not real to improve input by changing the way you activate the keys. Finally voice recognition use the association of phonemes and written text to allow you to input text. Each technique has different advantages and weakness. Graffiti may be slower than the keyboard but it is very fast to learn and can be used in constrained spaces. A good thing to do before going further is to try to establish some guidelines and principles that we can use to guide decisions later. After thinking for a while, I came up with the following dos and dont's for text input methods:
Ideally we would want something that is fast to learn and use. Something as intuitive as drawing a letter and as accurate and fast as the keyboard. When we consider the application in virtual environments, where the user does not have a physical keyboard, further restrictions apply. Many interesting ideas are ruled out from the beginning because they simply add more complexity to an existing input system. If you are selecting a letter, anything more than just pointing at it will not present a real gain. The only exception would be just looking at it instead of pointing with a device or your hand. If we want a method that is easy to learn we are pretty stuck with using a common known letter layout (qwerty or alphabetically), speech or drawing. Even with the advent of the GUI, touchscreen and voice recognition, the basic mechanism for text input remained mostly unchanged for more than 100 years. The keyboard and the QWERTY layout are still the most widely used method and still the fastest one. The qwerty layout was developed in 1868 to be used int railroad ticket typewriting. After that many changes were made in the layout to try to improve the speed, the most famous being the DVORAK. Anyway typing is quite fast. The world record is 216 words per minute, achieved on an electrical typewriter in 1968. The average typists is able to achieve 40 words per minute. Check the infographic and measure your own speed. Mobile devices, have reduced space to house a full keyboard and virtual ones also lack haptic feedback. This makes typing more challenging. To cope with this restrictions, most mobile keyboards utilize some kind of input prediction to correct words half typed or mistyped. This is an on going competition with several contenders such as swype, flesky, swiftkey and so on. The great majority, however, are still variations of the original QWERTY keyboard.
When thinking about text input in immersive environments the situation gets further complicated. Besides the lack of haptic feedback for keys there is also a loss of the reference frame. If you want to keep your hands away from a solid surface you eventually move away from the keyboard or cannot keep stroking at the same positions. I believe that a good text input method will be necessary to increase the range of applications using gestures and VR.
Researchers have come up with a lot different ideas for more natural or efficient text input in theses conditions. However, none seems to have been established as a good solution for now, which is unfortunate. For more information see: input methods  Watching computer appearances in movies is always interesting. It is fun to imagine if computer technology would really work in the way presented by Hollywood. Sometimes they manage to get computer scientists very puzzled though. Click at the image on the side to read three plausible explanations to a question whose answer has eluded many for years (Courtesy Wolf Gnards). When done right, however, movies with futuristic elements are a great opportunity to see new ideas and concepts from very skilled designers. Besides incredible motion graphics, most Sci-FI movies routinely present some kind of advanced display or interface. One recurrent ideia is the combination of holograms and 3d interaction with gestures. You can see it in several movies such as Tron, Iron Man and my favorite, District 9. These sort of motion control interfaces are well fitted for movies, but what they mean to real world designs? Leap Motion has created a nice two part video and post inspired by an analysis written by Noessel for Smashing Magazine. The video points out that even though movies seldom portray the reality, they do create expectation on the users for:
These are nice guidelines but perhaps they are too general to help us with the specific goal of building better gestural interfaces. As a user you always want to be in control, not the opposite. It is also complex to require both immersion and flow. Not all applications provide immersion and flow is hardly a property of the interface alone. In Noessel article, however, he observes that gesture in movies tend to fall into 7 different type of actions:
These actions are almost a 1:1 mapping to real world gestures. So they tend to feel more intuitive and even advanced (on the sense that they understand what you mean). This set some guidelines on what users may expect from those gestures. The most interesting point by Noessels is really about the role of language in interfaces, but I will discuss it later. If you are interested, NoteLoop has an interesting blog with a section dedicated to Movie UI.
Natural User Interfaces (NUI) still lacks a formal definition. It can appear as a synonym for intuitive, easy or gesture based interaction. So rather than trying to define one I will list some characteristics that are usually associated with them:
If you are new to the term, this is a cool video that has some examples and attempts to define some concepts: In video games, the use of more natural interfaces helped technology intimidated people to get the courage to jump in and play. Even if most hard-core gamers still prefer classic game controllers, these new interaction techniques really helped to expand the market for videogame consoles. Bowling with the Wiimote seems more natural and simple than using a combination of buttons and analog sticks. The Nintendo Wii, Playstation Move and Microsoft Kinect are successful technologies that opened the path to development of more natural interactions for videogames. It is hard to talk about an absolute natural interface, but the previous example shows that one interface can feel more natural than another. The extent of this feeling depends not only on the technology but also on the activity being performed and the actual user of the interface. This further complicate the issue since NUI relies on previous background knowledge about how things are supposed to work. This assumptions are ultimately related to culture and previous experience of each user. With a few exceptions most user interfaces are a coolest but not so efficient way to perform a task. If we look closely we can see that in few examples, some actions performed are far from being natural. Even int the coolest complex hand/head/spirit tracking setup. In fact, a natural interaction does not require complex multiple degrees of freedom setup. Its quality emerge from the perfect coupling between the hardware, the software, the task and the user. More on that latter. Or not. I would like to talk a little about my new area of study. Coming from computer graphics research it is going to be very fun and challenging to learn the diversity of techniques and subtleties of the field. Human Computer Interaction (HCI) deals with the interface between computers and people. It seeks to understand how humans behave when performing actions and interpreting computer output. At the same time it tries to develop new technologies or paradigms that can be useful to make this communication better. The difficulties arise because we do not understand well how our brain and perception works. What are its limits and capabilities ? Computers operate on a way that is quite different from us and even the most power computer pale in comparison to small prodigies of the human mind. However computers are very useful in many specifics tasks and that is the motivation behind most research in computing. Researchers in HCI generally employ a multidisciplinary approach when trying to devise better interaction models. One can get support from disciplines such as cognitive sciences, ergonomics, graphics design, engineering, ethnography, etc. Designs are also based on different metaphors and ideas. Windowed interfaces, for example, are available in most computers. They are based on discrete visualization areas, that you can move around, open an close, each one associated with a specific document or software. Windows like these only exists on the display and do not really represent anything. They are just abstractions that work really well. Depending on display, you can use a mouse, keyboard or touch screen to interact. Tangible User Interfaces, on the other hand, try to associate information and actions with physical entities. In this way information can have a presence in the real world: you can grab, move, combine it with your hands. This mapping needs not be static and may change depending on the context. There are a couple of really interesting experiments with this idea.  Reactable tangible interface (photo by Daniel Williams) Interfaces that are instinctive and employ mappings that are well fitted to the task or situation are called Natural User Interfaces. This approach generally makes use of more advanced techniques such as gesture recognition and head tracking to allow direct manipulation of virtual elements. This is a way to enable the use of our real world knowledge and expectations when interacting with the computer.  Tom Cruise operating a "natural user interface" in the minority report movie. Human computer interaction is an exciting field that is evolving constantly by new theoretical perspectives, technology developments and a better understanding of the human being. Stay tuned! Quick links: |
Wallace Lages
Assistant professor and entrepreneur. Archives
May 2015
Categories |


 RSS Feed
RSS Feed